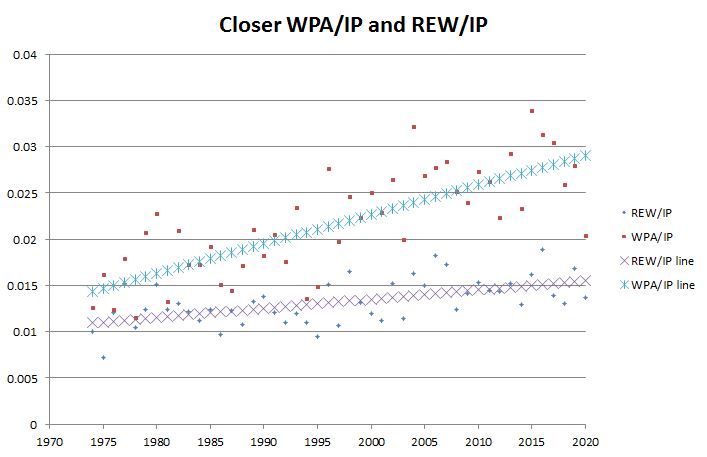
What does it mean to talk about the uncertainty in, say, a pitcher’s ERA or a hitter’s OBP? You know exactly how many ER were allowed, exactly how many innings were pitched, exactly how many times the batter reached base, and exactly how many PAs he had. Outside of MLB deciding to retroactively flip a hit/error decision, there is no uncertainty in the value of the stat. It’s an exact measurement. Likewise, there’s no uncertainty in Trout’s 2013 wOBA or wRC+. They reflect things that happened, calculated in deterministic fashion from exact inputs. Reporting a measurement uncertainty for any of these wouldn’t make any sense.
The Statcast metrics are a little different- EV, LA, sprint speed, hit distance, etc. all have a small amount of random error in each measurement, but since those errors are small and opportunities are numerous, the impact of random error is small to start with and totally meaningless quickly when aggregating measurements. There’s no point in reporting random measurement uncertainty in a public-facing way because it may as well be 0 (checking for systematic bias is another story, but that’s done with the intent of being fixed/corrected for, not of being reported as metric uncertainty).
Point 1:
So we can’t be talking about the uncertainties in measuring/calculating these kinds of metrics- they’re irrelevant-to-nonexistent. When we’re talking about the uncertainty in somebody’s ERA or OBP or wRC+, we’re talking about the uncertainty of the player’s skill at the metric in question, not the uncertainty of the player’s observed value. That alone makes it silly to report such metrics as “observed value +/- something”, like ERA 0.37 +/- 3.95, because it’s implicitly treating the observed value as some kind of meaningful central-ish point in the player’s talent distribution. There’s no reason for that to be true *because these aren’t talent metrics*. They’re simply a measure of something over a sample, and many such metrics frequently give values where a better true talent is astronomically unlikely to be correct (a wRC+ over 300) or even impossible (an ERA below 0) and many less extreme but equally silly examples as well.
Point 2:
Expressing something non-stupidly in the A +/- B format (or listing percentiles if it’s significantly non-normal, whatever) requires a knowledge of the player’s talent distribution after the observed performance, and that can’t be derived solely from the player’s data. If something happens 25% of the time, talent could cluster near 15% and the player is doing it more often, talent could cluster near 35% and the player is doing it less often, or talent could cluster near 25% and the player is average. There’s no way to tell the difference from just the player’s stat line and therefore no way to know what number to report as the mean, much less the uncertainty. Reporting a 25% mean might be correct (the latter case) or as dumb as reporting a mean wRC+ of 300 (if talent clusters quite tightly around 15%).
Once you build a prior talent distribution (based on what other players have done and any other material information), then it’s straightforward to use the observed performance at the metric in question and create a posterior distribution for the talent, and from that extract the mean and SD. When only the mean is of interest, it’s common to regress by adding some number of average observations, more for a tighter talent distribution and fewer for a looser talent distribution, and this approximates the full Bayesian treatment. If the quantity in the previous paragraph were HR/FB% (league average a little under 15%), then 25% for a pitcher would be regressed down a lot more than for a batter over the same number of PAs because pitcher HR/FB% allowed talent is much more tightly distributed than hitter HR/FB% talent, and the uncertainty reported would be a lot lower for the pitcher because of that tighter talent distribution. None of that is accessible by just looking at a 25% stat line.
Actual talent metrics/projections, like Steamer and ZiPS, do exactly this (well, more complicated versions of this) using talent distributions and continually updating with new information, so when they spit out mean and SD, or mean and percentiles, they’re using a process where those numbers are meaningful, getting them as the result of using a reasonable prior for talent and therefore a reasonable posterior after observing some games. Their means are always going to be “in the middle” of a reasonable talent posterior, not nonsense like wRC+ 300.
Which brings us to DRC+.. I’ve noted previously that the DRC+ SDs don’t make any sense, but I didn’t really have any idea how they were coming up with those numbers until this recent article, and a reference to this old article on bagging. My last two posts pointed out that DRC+ weights way too aggressively in small samples to be a talent metric and that DRC+ has to be heavily regressed to make projections, so when we see things in that article like Yelich getting assigned a DRC+ over 300 for a 4PA 1HR 2BB game, that just confirms what we already knew- DRC+ is happy to assign means far, far outside any reasonable distribution of talent and therefore can’t be based on a Bayesian framework using reasonable talent priors.
So DRC+ is already violating point 1 above, using the A +/- B format when A takes ridiculous values because DRC+ isn’t a talent metric. Given that it’s not even using reasonable priors to get *means*, it’s certainly not shocking that it’s not using them to get SDs either, but what it’s actually doing is bonkers in a way that turns out kind of interesting. The bagging method they use to get SDs is (roughly) treating the seasonal PA results as the exact true talent distribution of events, drawing from them over and over (with replacement) to get a fake seasonal line, doing that a bunch of times and taking the SD of the fake seasonal lines as the SD of the metric.
That’s obviously just a category error. As I explained in point 2, the posterior talent uncertainty depends on the talent distribution and can’t be calculated solely from the stat line, but such obstacles don’t seem to worry Jonathan Judge. When talking about Yelich’s 353 +/- 6 DRC+, he said “The early-season uncertainties for DRC+ are high. At first there aren’t enough events to be uncertain about, but once we get above 10 plate appearances or so the system starts to work as expected, shooting up to over 70 points of probable error. Within a week, though, the SD around the DRC+ estimate has worked its way down to the high 30s for a full-time player.” That’s just backwards about everything. I don’t know (or care) why their algorithm fails under 10 PAs, but writing “not having enough events to be uncertain about” shows an amazing misunderstanding of everything.
The accurate statement- assuming you’re going in DRC+ style using only YTD knowledge of a player- is “there aren’t enough events to be CERTAIN about of much of anything”, and an accurate DRC+ value for Yelich- if DRC+ functioned properly as a talent metric- would be around 104 +/- 13 after that nice first game. 104 because a 4PA 1HR 2BB game preferentially selects- but not absurdly so- for above average hitters, and a SD of 13 because that’s about the SD of position player projections this year. SDs of 70 don’t make any sense at all and are the artifact of an extremely high SD in observed wOBA (or wRC+) over 10-ish PAs, and remember that their bagging algorithm is using such small samples to create the values. It’s clear WHY they’re getting values that high, but they just don’t make any sense because they’re approaching the SD from the stat line only and ignoring the talent distribution that should keep them tight. When you’re reporting a SD 5 times higher than what you’d get just picking a player talent at random, you might have problems.
The Bayesian Central Limit Theorem
I promised there was something kind of interesting, and I didn’t mean bagging on DRC+ for the umpteenth time, although catching an outright category error is kind of cool. For full-time players after a full season, the DRC+ SDs are actually in the ballpark of correct, even though the process they use to create them obviously has no logical justification (and fails beyond miserably for partial seasons, as shown above). What’s going on is an example of the Bayesian Central Limit Theorem, which states that for any priors that aren’t intentionally super-obnoxious, repeatedly observing i.i.d variables will cause the posterior to converge to a normal distribution. At the same time, the regular Central Limit Theorem means that the distribution of outcomes that their bagging algorithm generates should also approach a normal distribution.
Without the DRC+ processing baggage, these would be converging to the same normal distribution, as I’ll show with binomials in a minute, but of course DRC+ gonna DRC+ and turn virtually identical stat lines into significantly different numbers
| NAME |
YEAR |
PA |
1B |
2B |
3B |
HR |
TB |
BB |
IBB |
SO |
HBP |
AVG |
OBP |
SLG |
OPS |
ISO |
oppOPS |
DRC+ |
DRC+ SD |
| Pablo Sandoval |
2014 |
638 |
119 |
26 |
3 |
16 |
244 |
39 |
6 |
85 |
4 |
0.279 |
0.324 |
0.415 |
0.739 |
0.136 |
0.691 |
113 |
7 |
| Jacoby Ellsbury |
2014 |
635 |
108 |
27 |
5 |
16 |
241 |
49 |
5 |
93 |
3 |
0.271 |
0.328 |
0.419 |
0.747 |
0.148 |
0.696 |
110 |
11 |
Ellsbury is a little more TTO-based and gets an 11 SD to Sandoval’s 7. Seems legit. Regardless of these blips, high single digits is about right for a DRC+ (wRC+) SD after observing a full season.
Getting rid of the DRC+ layer to show what’s going on, assume talent is uniform on [.250-.400] (SD of 0.043) and we’re dealing with 1000 Bernoulli observations. Let’s say we observe 325 successes (.325), then when we plot the Bayesian posterior talent distribution and the binomial for 1000 p=.325 events (the distribution that bagging produces)
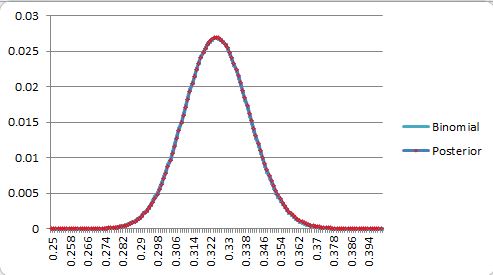
They overlap so closely you can’t even see the other line. Going closer to the edge, we get, for 275 and 260 observed successes,
At 275, we get a posterior SD of .13 vs the binomial .14, and at 260, we start to break the thing, capping how far to the left the posterior can go, and *still* get a posterior SD of .11 vs .14. What’s going on here is that the weight for a posterior value is the prior-weighted probability that that value (say, .320) produces an observation of .325 in N attempts, while the binomial bagging weight at that point is the probability that .325 produces an observation of .320 in N attempts. These aren’t the same, but under a lot of circumstances, they’re pretty damn close, and as N grows, and the numbers that take the place of .320 and .325 in the meat of the distributions get closer and closer together, the posterior converges to the same normal that describes the binomial bagging. Bayesian CLT meets normal CLT.
When the binomial bagging variance starts dropping well below the prior population variance, this convergence starts to happen enough to where the numbers can loosely be called “close” for most observed success rates, and that transition point happens to come out around a full season of somewhat regressed observation of baseball talent. In the example above, the prior population SD was 0.043 and the binomial variance was 0.014, so it converged excellently until we ran too close to the edge of the prior. It’s never always going to work, because a low end talent can get unlucky, or a high end talent can get lucky, and observed performance can be more extreme than the talent distribution (super-easy in small samples, still happens in seasonal ones) but for everybody in the middle, it works out great.
Let’s make the priors more obnoxious and see how well this works- this is with a triangle distribution, max weight at .250 straight line down to a 0 weight at .400.

290 successes, .0143 vs .0140

325 successes, .0144 vs .0148

350 successes, .0143 vs .0151

350 successes, .0143 vs .0151
325 successes, .0144 vs .0148

290 successes, .0143 vs .0140
The left-weighted prior shifts the means, but the standard deviations are obviously about the same again here. Let’s up the difficulty even more, starting with a N(.325,.020) prior (0.020 standard deviation), which is pretty close to the actual mean/SD wOBA talent distribution among position players (that distribution is left-weighted like the triangle too, but we already know that doesn’t matter much for the SD)

360 successes, .012 vs .015

325 successes, .012 vs .015

290 successes, .012 vs .013
Even now that the bagging distributions are *completely* wrong and we’re using observations almost 2 SD out, the standard deviations are still .014-.015 bagging and .012 for the posterior. Observing 3 SD out isn’t significantly worse. The prior population SD was 0.020, and the binomial bagging variance was 0.014, so it was low enough that we were close to converging when the observation was in the bulk of the distribution but still nowhere close when we were far outside, although the SDs of the two were still in the ballpark everywhere.
Using only 500 observations on the N(.325,.020) prior isn’t close to enough to pretend there’s convergence even when observing in the bulk.
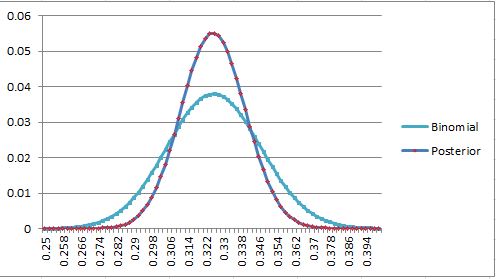
The posterior has narrowed to a SD of .014 (around 9 points of wRC+ if we assume this is wOBA and treat wOBA like a Bernoulli, which is handwavy close enough here), which is why I said above that high-single-digits was “right”, but the binomial variance is still at .021, 50% too high. The regression in DRC+ tightens up the tails compared to “binomial wOBA”, and it happens to come out to around a reasonable SD after a full season.
Just to be clear, the bagging numbers are always wrong and logically unjustified here, but they’re a hackjob that happens to be “close” a lot of the time when working with the equivalent of full-season DRC+ numbers (or more). Before that point, when the binomial bagging variance is higher than the completely naive population variance (the mechanism for DRC+ reporting SDs in the 70s, 30s, or whatever for partial seasons), the bagging procedure isn’t close at all. This is just another example of DRC+ doing nonsense that looks like baseball analysis to produce a number that looks like a baseball stat, sometimes, if you don’t look too closely.