Maybe. Quite possibly. Something strange is going on.
For the TL;DR crowd
- Season 6 EU playoff viewership (Sunday October 14, 2018) was abominably low, off by 10,000-20,000 viewers or up to a third of the regular audience, far worse than any other broadcast this season.
- Season 6 NA regional playoffs, held the day before (Saturday, October 13, 2018) were exactly in line with seasonal numbers.
- Regional playoff viewership was always fine-to-good for the other 7 Season 3-Season 6 regional playoff broadcasts
- There was an unnatural 15,000ish viewer bump late in the broadcast that can only realistically be a big host or major viewbot fraud
- Psyonix won’t comment at all and I can’t find other evidence of a large host
- Viewership of major events was trending way down coming into season 6
Background
The Rocket League Championship Series (RLCS) is a biannual competition featuring 8 teams from North America (NA), 8 teams from Europe (EU), and 8 teams from Oceania (OCE) each playing an online single-round-robin season over 5 weeks followed by an online regional playoff. The top 4 teams from NA and EU and the top 2 teams from OCE then meet in person to crown the world champion for that season. Psyonix, the maker of Rocket League, runs the NA and EU competitions and broadcasts every game on its Twitch stream. A different entity is responsible for OCE and broadcasts those games on its own Twitch stream instead. We won’t worry about the OCE broadcasts.
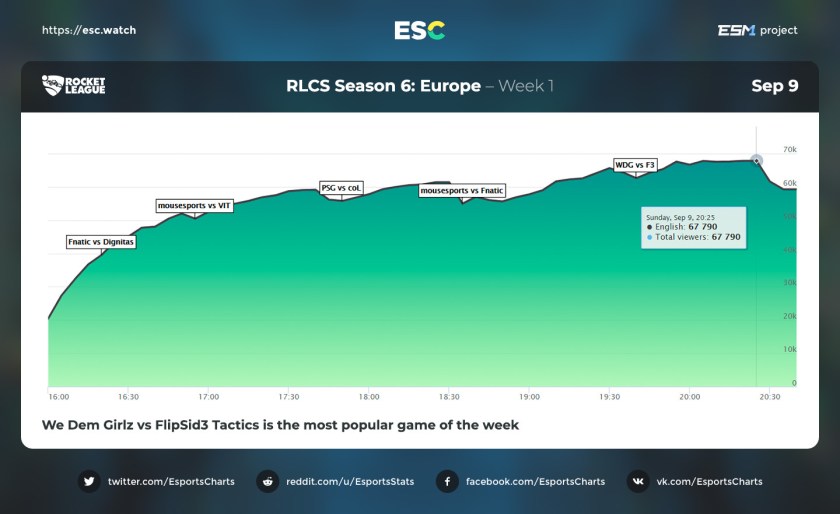
Viewer counts increased significantly between seasons 3 and 4, slightly between 4 and 5, and were down about 20% in the current season 6, as the following graphs from esc.watch, an esports viewership tracker, show. I have personally spot-checked esc.watch’s Rocket League charts over the past year and have always found them accurate.

click to enlarge

click to enlarge
The focus of this post will be the large decline in the season 6 EU playoff. Note that season 3 NA has a slight decline in playoff viewership while every other playoff broadcast has been up or at least flat. File that away for later. A couple of other easily explainable anomalies need to be addressed first. In season 3 (green), there was a week off between week 3 (April 2, 2017) and week 4 (April 16, 2017). That resulted in lower viewership in week 4 in both NA and EU that rebounded to “normal” in the following 2 weeks of consecutive play. Season 5 week 5 in EU had a large technical problem. A power outage near the Psyonix studio cut the broadcast short after 2 games and the remaining 4 games were rescheduled for 12 PM Eastern on a Thursday in place of the regular 12 PM Eastern on Sunday. That timeslot is obviously terrible in comparison for NA viewers and the low viewer count is quite understandable. Season 4 week 5 in EU had a different technical problem. The broadcast was fine, but twitch.tv did not send out notifications that the broadcast was starting and reportedly didn’t even show the Rocket League channel as being online. Given the nature of viewership, which will be discussed next, it’s also quite understandable for that number to be in the toilet.
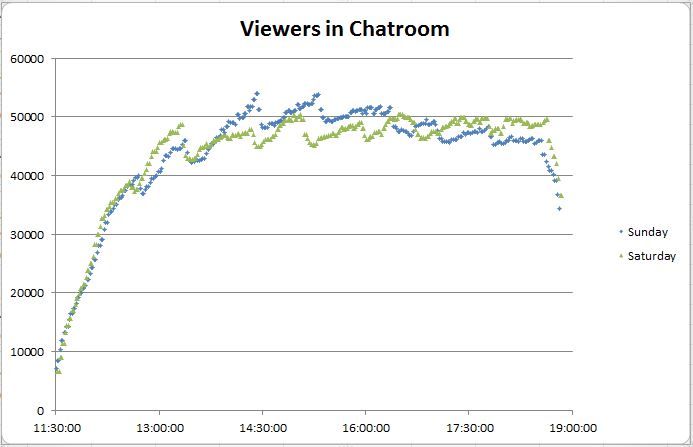
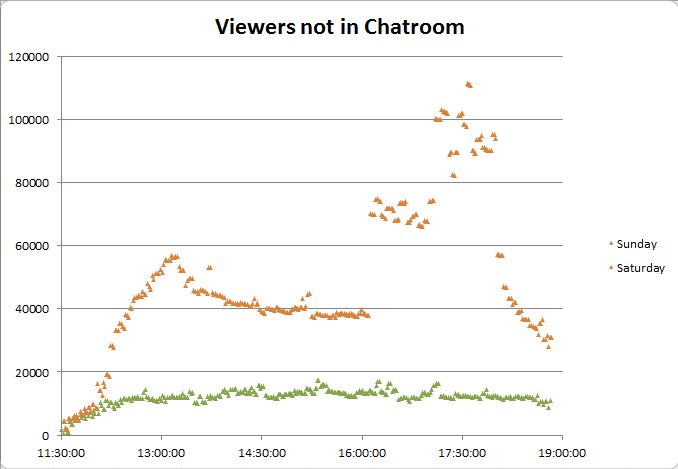
A typical RLCS broadcast accumulates most of its viewers over its first three matches like this (another reason that the EU S5 Week 5 broadcast being cut off after 2 games killed the viewership).
The viewership accumulates this way because it’s comprised of hardcore viewers, those who are ready for the start of the broadcast every week, or at least the notification for it, and those who happen upon it in progress. People who follow the RL Twitch stream and connect to Twitch will see that it’s online, and people who play Rocket League while a broadcast is in progress are greeted with a giant flashing “ESPORTS LIVE NOW” button on the main menu that they can click to watch.
EU Regionals Anomalies
The graphs for the 12 broadcasts this season follow. Don’t pay attention to the actual numbers yet, just the shapes. And in particular the last graph on the bottom right, the EU playoffs.

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge

click to enlarge
There are two obvious things of note. First, the glitch on the left is the very end of EU Week 5 (the bottom left image above) and not actually part of the playoff broadcast. That was confirmed directly by esc.watch. Second.. well…

That’s a near-instantaneous (under 5 minute) jump of almost 15,000 viewers, and there’s no precedent of such a thing in any other broadcast this season. It’s clearly not part of the natural accumulation process.
EU Regionals Low Viewership
The other interesting thing about this broadcast is that it was the least viewed broadcast of the season by a country mile.

Or in slightly less cluttered form, for each region, the averages of the regular season (weeks 1-5), the playoffs, and the difference between the playoff viewership and the regular season viewership.
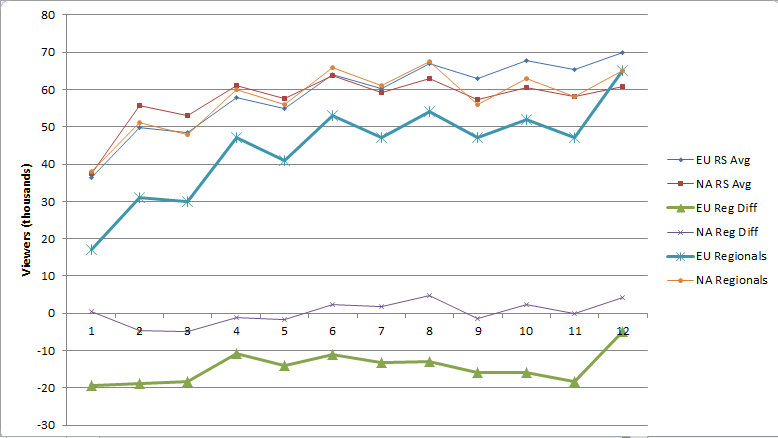
Yikes? To summarize so far, we have a mystery with the following facts
- Season 6 EU playoff viewership (Sunday October 14, 2018) was abominably low, off by 10-20 thousand viewers or up to a third of the regular audience, far worse than any other broadcast this season.
- Season 6 NA regional playoffs, held the day before (Saturday, October 13, 2018) were exactly in line with seasonal numbers.
- Regional playoff viewership was always fine-to-good for the other 7 Season 3-Season 6 regional playoff broadcasts
- There was an unnatural 15,000ish viewer bump late in the broadcast.
Potential Causes for Low Viewership
In investigating the low viewership, I was unable to uncover any evidence of technical difficulties. I was watching the broadcast and using Twitch and both worked fine. I found no reports of issues, Twitch-wise or internet-wise, in the relevant reddit thread while gripes about the Twitch issues in season 4 were plentiful. The graph of viewer count was accurate. I personally observed the extremely low viewer counts throughout as well as the high viewer count at the end. Unfortunately I wasn’t paying attention to the count as the 15,000 viewers showed up late. Technical issues don’t seem to be the explanation here.
The second possibility is that something external was drawing would-be viewers away. There wasn’t any news in the world that day that would have diverted a large number of viewers. Call of Duty: Black Ops 4 was released worldwide on October 12, but if that were the cause, it should have sunk the NA playoff viewership on October 13 as well. Similarly, Rocket League itself was offering a double-XP weekend, giving out more in-game rewards for playing, but that was also active on Saturday during the NA playoffs. There were other non-Rocket League esports events, as there are many weekends, but there didn’t appear to be anything that could uniquely sink the entire Sunday broadcast or the first 90% of it. This doesn’t appear to be it either.
The third possibility is that the broadcast itself was thought to be uniquely unappealing to tune into, presumably because Dignitas, the two-time defending world championship roster that just went 7-0 in round robin play, was thought to be a lock to win. This explanation falls short for several reasons. First, there’s no evidence that Dignitas is bad for viewership at all. None of their matches have seen strange declines and the last match of the regular season was an almost meaningless Dignitas match and it had the highest viewership of the week. The idea that people would watch to see if Dignitas could go 7-0, then disappear in droves as Dig tried to become the first NA/EU team to go 7-0 and win the regional playoffs… well, that’s just strange.
The format of the regional championship also undercuts that explanation. It’s a 6-team single elimination where the top 4 qualify for the world championship. The top 2 seeds get first-round byes and automatically qualify which means the first two matches- #3 vs #6 and #4 vs #5- are critical. The winner goes to the world championships and the loser is done for the season. Even if people didn’t want to watch the rest of the playoffs, those matchups should have been compelling. The second match of the day involved the most anticipated rookie in RLCS history by far, ScrubKilla, and his wildly inconsistent Renault Vitality team playing for a LAN spot. This should have been a must-watch series, and by one metric it was. Not counting the first match of the day, which always accumulates lots of viewers, Vitality-PSG had a higher accumulation of viewers (+17k) than any other match had all season, almost 50% clear of second place. People talked about ScrubKilla and Vitality all season. Viewers appeared to tune in in numbers specifically to not miss this match. The final number shouldn’t have been hot garbage, and yet it still was. I’m at a complete loss for a legitimate explanation for the overall low viewership.
Potential Causes of the 15,000 Viewer Bump
Switching focus to the ~15,000 viewer bump, there’s one legitimate explanation- a large stream from another game/scene hosted them.. That would bump the viewer count up quickly, but I could find no evidence of that actually happening. I couldn’t find a mention on twitter. I watched the relevant portion of the broadcast replay, focusing on the Twitch chat (bless my soul), and there weren’t any mentions of a host, nor any newbie-like comments, which seems a bit unlikely. In addition, the attrition rate would have had to have been extremely low because viewership also went up a tad after the spike. Rocket League being the autoplay stream on the Twitch homepage was suggested as a possibility, but after observing those streams for a few days, none I saw were accumulating viewers at even a meaningful fraction of the necessary rate.
If the 15,000 viewer bump isn’t natural viewer accumulation, and isn’t a legitimate Twitch host, that leaves fraud. Psyonix randomly gives away in-game items to players who watch the stream and have their Twitch accounts linked. This is absolutely a boon to viewership, and can be misleading in a way because players can and do load the stream, mute it, and pay no attention to it just for the chance of getting a drop. In this way, the percentage of the viewer count who are watching the stream is lower than it otherwise would be, but this is all out in the open, and it does also further a legitimate purpose of trying to entice players to become esports viewers. Where there are giveaways, there are people trying to exploit giveaways, but the likelihood of large-scale fraud here seems very small to me. The expected value in terms of reselling items of having a linked account watch a stream for 6 hours is about 25-50 cents (USD), and obtaining that value across thousands of accounts involves selling numerous small-ticket (.50-$3) items that nobody wants multiples of. While I have no doubt that some people sign up a few accounts and have Twitch open in multiple browsers, any person or group capable of controlling enough computers/IPs to generate 15,000 concurrent fraudulent Twitch views should be able to make a hell of a lot more money doing almost anything else with them…
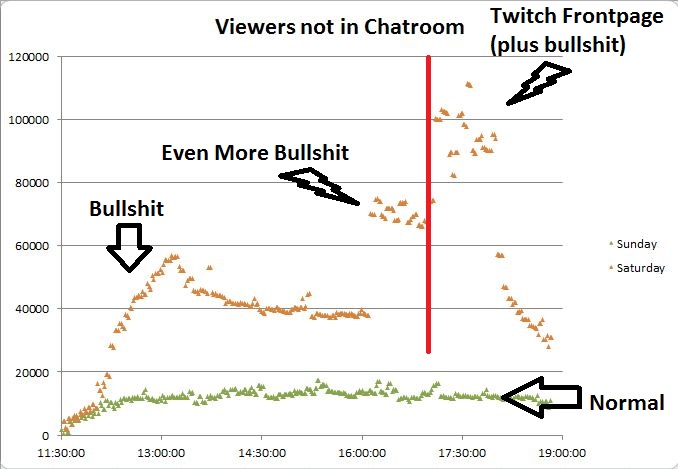
Such as selling their services to a company/streamer that wants to inflate its viewer count to bring in more advertising/sponsorship revenue or to just appear to be more popular than it actually is. This is called viewbotting, and it’s not a rare occurrence. If Psyonix had an arrangement for around 15,000 viewbots and forgot to turn them on before the last match, or never turned them on and got a 15,000 viewer host near the end, this would explain everything. Here’s the graph from earlier with 15,000 viewers added through the whole broadcast instead of the very end.

That would be much more consistent with the regular season. I obviously have no affirmative proof that Psyonix is committing viewbot fraud, but if they were committing viewbot fraud, this is *exactly* what it would look like if they screwed up for a week, and I’m at a complete loss for legitimate explanations for the low viewership that wouldn’t also have sunk the NA playoffs.
In summary, the evidence here is consistent with several main hypotheses of varying plausibility.
- There is a legitimate, as yet undiscovered reason for the overall low viewership and they got a big host of around 15,000 near the end.
- Psyonix is viewbotting around 15,000 fakes and forgot to turn them on until the last match of the day.
- Psyonix is viewbotting around 15,000 fakes, forgot to turn them on at all that day, and coincidentally got a big host of around 15,000 near the end.
Psyonix’s Refusal to Comment
I contacted Psyonix a fourth time with the article up to this point and another request for comment. That’s private messages to Murty Shah and Cory Lanier, the two main public faces of their esports program, an email to Psyonix’s general PR contact address, and an email to Psyonix’s esports contact address, and I’ve received no replies. In addition, they didn’t comment in reddit threads where the low viewership and the big bump were discussed. The lack of response has to be considered deliberate at this point. Let’s think about what that means.
Hypothetically, if Psyonix knows the viewers are from a host, would they be willing to tell the world about it? I would think so. I’m not a social media guru, but if somebody from a different game added 15k viewers to my 48k viewer broadcast, I would want to say thank you, and I’d want to say it publicly to attempt to engage their followers a little more. They shouldn’t do that for small hosts because that would bring a barrage of useless attention-seekers, and I’m not sure exactly where the acknowledgment line should be drawn, but a 15,000 viewer host seems safely big enough at this point. Furthermore, there’s no obvious benefit to attempting to conceal that a host happened. It would already be known to the people watching the other stream, it’s obvious to everybody who looked at the viewer graph that something happened, and it’s inconceivable to me that a channel from a different scene wanting to expose its viewers to Rocket League could be construed negatively. Now watch it turn out that Psyonix is slowrolling and waiting for the article to go live to say who the host was, but I have to work with what I have so far. If they do decide to announce who the host was and it’s legit, then we’re just back to the mystery of the low viewership in general.
Hypothetically, if Psyonix knows the viewers are fake, would they be willing to deny that they were hosted or willing to lie about who hosted them? The latter would be a huge mistake because it would be discovered in no time flat, and the former is straight-up admitting that the numbers for that broadcast are bogus, and by inference, that the numbers for every other broadcast during the season are almost certainly bogus. They have to stay silent in this case and hope it blows over. Twitch itself should have an active interest in investigating this broadcast if there wasn’t a big host.
Reasons for Viewbotting
The cleanest explanation for not commenting is fraud, which invites the question of whether or not viewbotting would make any sense. As a moral matter, I have absolutely no idea if the relevant people working there are the type who could do such a thing. As a business matter, it’s plausible. Before this season, viewership trends started out ok and then took a straight-line path to dumpster fire. All tournament pairs below are roughly equivalent across seasons. Broadcasts were about the same length and Fan Rewards were active for all referenced broadcasts. This is what Psyonix was looking at for average viewers as the numbers rolled in this year
- April 22. RLCS Season 5: 68.2k, +15% over season 4
- May 6. Promotion/Relegation Tournament. 44.5k, +9% over season 4
- June 10. World Championships. 101.8k, -5% from season 4 and -14% from season 3
- August 11. UORL 2 final qualifiers. 15.1k. esc.watch doesn’t have comps for last year, and timeslots are wonky, but this is not a good number at all for top players playing with rewards active. The peak viewership was only 29.5k, presumably on one of the four good weekend timeslots.
- August 26. Universal Open 2. 29.1k, -35% from last year
- September 2. Season 6 play-ins 42.0k -46% from last season.
If I were in charge of the esport or somebody whose job/livelihood depended on the continued success of the esport, I would have been very nervous going into season 6. It’s not hard to see the appeal of buying some “insurance viewers” in that climate. As it was, season 6 viewership was officially down 20% across the board, and the real number is much worse if this season was being viewbotted. To repeat one last time, I have no definitive proof that viewbotting took place. It is only a hypothesis that explains viewer stats and Psyonix’s behavior.
Conclusion
I hope, and all fans of Rocket League probably join me in hoping that there was a legitimate reason for the low viewership and that Psyonix is simply being obnoxious refusing to acknowledge a large host. Anything else would be a huge story and a crippling blow to the future of the esport. If Twitch or Psyonix comment, the article will be updated to reflect that. Many thanks to esc.watch for providing the charts for this article.