Edit: A summary, including some updates, is now at https://hareeb.com/2022/02/02/one-last-rating-update/
Note: If you’re playing in numbered Mythic Constructed during the rest of May, and/or you’d like to help me crowdsource enough logfiles to get a full picture of the Rank # – Rating relationship during the last week, please visit https://twitter.com/Hareeb_alSaq/status/1397022404363395079 and DM/share. If I get enough data, I can make a rank-decay curve for every rank at once, among other things.
Brought to you by the all-time undisputed king of the percent gamers

Apologies for the writing- Some parts I’d written before, some I’m just writing now, but there’s a ton to get out, a couple of necessary experiments weren’t performed or finished yet, and I’m sure I’ll find things I could have explained more clearly. The details are also seriously nerdy, so reading all of this definitely isn’t for everybody. Or maybe anybody.
TL;DR
- There is rating-based pairing in ranked constructed below Mythic (as well as in Mythic).
- It’s just as exploitable as you should think it is
- There is no detectable Glicko-ness to Mythic constructed ratings in the second half of the month. It’s indistinguishable from base-Elo
- Expected win% is constrained to a ~25%-~75% range, regardless of rating difference, for both Bo1 and Bo3. That comes out to around 11% Mythic later in the month.
- After convergence, the Bo1 K-value is ~20.5. Bo3 K is ~45.
- The minimum change in rating is ~5 points in a Bo1 match and ~10 points in a Bo3 match.
- Early in the month, the system is more complicated.
- Performance before Mythic seems to have only slight impact on where you’re initially placed in Mythic.
- Giving everybody similar initial ratings when they make Mythic leads to issues at the end of the month.
- The change making Gold +2 per win/-1 per loss likely turbocharged the issues from #6
It’s well known that the rank decay near the end of the month in Mythic Constructed is incredibly severe. These days, a top-600 rating with 24 hours left is insufficient to finish top-1200, and it’s not just a last-day effect. There’s significant decay in the days leading up to the last day, just not at that level of crazy. The canonical explanations were that people were grinding to mythic at the end of the month and that people were playing more in the last couple of days. While both true, neither seemed sufficient to me to explain that level of decay. Were clones of the top-600 all sitting around waiting until the last day to make Mythic and kick everybody else out? If they were already Mythic and top-1200 talent level, why weren’t they mostly already rated as such? The decay is also much, much worse than it was in late 2019, and those explanations give no real hint as to why.
The only two pieces of information we have been given are that 1) Mythic Percentile is the percentage (Int(Your Rating/#1500 rating)) of the actual internal rating of the #1500 player. This is true. 2) Arena uses a modified Glicko system. Glicko is a modification of the old Elo system. This is, at best, highly misleading. The actual system does multiple things that are not Glicko and does not do at least one thing that is in Glicko.
I suspected that WotC might be rigging the rating algorithm as the month progressed, either deliberately increasing variance by raising the K-value of matches or by making each match positive-sum instead of zero-sum (i.e. calculating the correct rating changes, then giving one or both players a small boost to reward playing). Either of these would explain the massive collision of people outside the top-1200, who are playing, into the the people inside the top-1200 who are trying to camp on their rating. As it turns out, neither of those appear to be directly true. The rating system seems to be effectively the same throughout the last couple of weeks of the month, at least in Mythic. The explanations for what’s actually going on are more technical, and the next couple of sections are going to be a bit dry. Scroll down- way down- to the Problems section if you want to skip how I wasted too much of my time.
I’ve decided to structure this as a journal-of-my-exploration style post, so it’s clear why it was necessary to do what I was doing if I wanted to get the information that WotC has continually failed to provide for years.
Experiments:
Background
I hoped that the minimum win/loss would be quantized at a useful level once the rating difference got big enough, and if true, it would allow me to probe the algorithm. Thankfully, this guess turned out to be correct. Deranking to absurdly low levels let me run several experiments.
Under the assumption that the #1500 rating does not change wildly over a few hours in the middle of the month when there are well over 1500 players, it’s possible to benchmark a rating without seeing it directly. For instance, a minimum value loss that knocks you from 33% to 32% at time T will leave you with a similar rating, within one minimum loss value, as a 33%-32% loss several hours later. Also, if nothing else is going on, like a baseline drift, the rating value of 0 is equivalent over any timescale within the same season. This sort of benchmarking was used throughout.
Relative win-loss values
Because at very low rating, every win would be a maximum value win and every loss would be a minimum value loss, the ratio I needed to maintain the same percentile would let me calculate the win% used to quantize the minimum loss. As it turned out, it was very close to 3 losses for every 1 win, or a 25%-75% cap, no matter how big the rating difference (at Mythic). This was true for both Bo1 and Bo3, although I didn’t measure Bo3 super-precisely because it’s a royal pain in the ass to win a lot of Bo3s compared to spamming Mono-R in Bo1 on my phone, but I’m not far off whatever it is. My return benchmark was reached at 13 wins and 39 losses, which is 3:1, and I assumed it would be a nice round number. Unfortunately, as I discovered later, it was not *exactly* 3:1, or everybody’s life would have been much easier.
Relative Bo1-Bo3 K values
Bo3 has about 2.2 times the K value of Bo1. By measuring how many min-loss matches I had to concede in each mode to drop the same percentage, it was clear that the Bo3 K-value was a little over double the Bo1 K-value. In a separate experiment, losing 2-0 or 2-1 in Bo3 made no difference (as expected, but no reason not to test it). Furthermore, being lower rated and having lost the last match (or N matches) had no effect on the coin toss in Bo3. Again, it shouldn’t have, but that was an easy test.
Elo value of a percentage point
This is not a constant value throughout the month because the rating of the #1500 player increases through the month, but it’s possible to get an approximate snapshot value of it. Measuring this, the first way I did it, was much more difficult because it required playing matches inside the 25%-75% range, and that comes with a repeated source of error. If you go 1-1 against players with mirrored percentile differences, those matches appear to offset, except because the ratings are only reported as integers, it’s possible that you went 1-1 against players who were on average 0.7% below you (meaning that 1-1 is below expectation) or vice versa. The SD of the noise term from offsetting matches would keep growing and my benchmark would be less and less accurate the more that happened.
I avoided that by conceding every match that was plausibly in the 25-75% range and only playing to beat much higher rated players (or much lower rated, but I never got one, if one even existed). Max-value wins have no error term, so the unavoidable aggregate uncertainty was kept as small as possible. Using the standard Elo formula value of 400 (who knows what it is internally, but Elo is scale-invariant), the 25%-75% cap is reached at a 191-point difference, and by solving for how many points/% returned my variable-value losses to the benchmark where I started, I got a value of 17.3 pts/% on 2/16 for Bo1.
I did a similar experiment for Bo3 to see if the 25%-75% threshold kicked in at the same rating difference (basically if Bo3 used a number bigger than 400). Gathering data was much more time-consuming this way, and I couldn’t measure with nearly the same precision, but I got enough data to where I could exclude much higher values. It’s quite unlikely that the value could have been above 550, and it was exactly consistent with 400, and it’s unlikely that they would have bothered to make a change smaller than that, so the Bo3 value is presumably just 400 as well.
This came out to a difference of around 11% mythic being the 25-75% cap for Bo1 and Bo3, and combined with earlier deranking experiments, a K-value likely between 20-24 for Bo1 and 40-48 for Bo3. Similar experiments on 2/24 gave similar numbers. I thought I’d solved the puzzle in February. Despite having the cutoffs incorrect, I still came pretty close to the right answer here.
Initial Mythic Rating/Rating-based pairing
My main account made Mythic on 3/1 with a 65-70% winrate in Diamond. I made two burners for March, played them normally through Plat, and then diverged in Diamond. Burner #1 played through diamond normally (42-22 in diamond, 65-9 before that). Burner #2 conceded hundreds of matches at diamond 4 before trying to win, then went something like 27-3 playing against almost none of the same decks-almost entirely against labors of jank love, upgraded precons, and total nonsense. The two burners made Mythic within minutes of each other. Burner #1 started at 90%. Burner #2 started at 86%. My main account was 89% at that point (I’d accidentally played and lost one match in ranked because the dogshit client reverted preferences during an update and stuck me in ranked instead of the play queue when I was trying to get my 4 daily wins). I have no idea what the Mythic seeding algorithm is, but there was minimal difference between solid performance and intentionally being as bad as possible.
It’s also difficult to overstate the difference in opponent difficulty that rating-based pairing presents. A trash rating carries over from month to month, so being a horrendous Mythic means you get easy matches after the reset, and conceding a lot of matches at any level gives you an easy path to Mythic (conceding in Gold 4 still gets you easy matches in Diamond, etc)
Lack of Glicko-ness
In Glicko, rating deviation (a higher rating deviation leads to a higher “K-value”) is supposed to decrease with number of games played and increase with inactivity. My main account and the two burners from above should have produced different behavior. The main account had craploads of games played lifetime, a near-minimum to reach Mythic in the current season, and had been idle in ranked for over 3 weeks with the exception of that 1 mistake game. Burner #1 had played a near-minimum number of games to reach Mythic (season and lifetime) and was currently active. Burner #2 had played hundreds more games (like 3x as many as Burner #1) and was also currently active.
My plan was to concede bunches of matches on each account and see how much curvature there was in the graph of Mythic % vs. expected points lost (using the 25-75 cap and the 11% approximation) and how different it was between accounts. Glicko-ness would manifest as a bigger drop in Mythic % earlier for the same number of expected points lost because the rating deviation would be higher early in the conceding session. As it turned out, all three accounts just produced straight lines with the same slope (~2.38%/K on 3/25). Games played before Mythic didn’t matter. Games played in Mythic didn’t matter. Inactivity didn’t matter. No Glicko-ness detected.
Lack of (explicit) inactivity penalty
I deranked two accounts to utterly absurd levels and benchmarked them at a 2:1 percentage ratio. They stayed in 2:1 lockstep throughout the month (changes reflecting the increase in the #1500 rating, as expected). I also sat an account just above 0 (within 5 points), and it stayed there for like 2 weeks, and then I lost a game and it dropped below 0, meaning it hadn’t moved any meaningful amount. Not playing appears to do absolutely nothing to rating during the month, and there doesn’t seem to be any kind of baseline drift.
At this point (late March), I believed that the system was probably just Elo (because the Glicko features I should have detected were clearly absent), and that the win:loss ratio was exactly 3:1, because why would it be so close to a round number without being a round number. Assuming that, I’d come up with a way to measure the actual K-value to high precision.
Measuring K-Value more precisely
Given that the system literally never tells you your rating, it may sound impossible to determine a K-value directly, but assuming that we’re on the familiar 400-point scale that Arpad Elo published that’s in common usage (and that competitive MTG used to use when they had such a thing), it actually is, albeit barely.
Assume you control the #1500-rated player and the #1501 player, and that #1501 is rated much lower than #1500. #1501 will be displayed as a percentile instead of a ranking. If you call the first percentile displayed you see 1501-A, then lose a (minimum value) match with the #1500 player, you’ll get a new percentile displayed, 1501B. Call the #1500’s initial rating X, and the #1501’s rating Y. This gives a solvable system of equations.
Y/X = 1501A and Y/(X-1 min loss) = 1501B.
This gives X and Y in terms of min-losses (e.g. X went from (+5.3 minlosses to +4.3 minlosses).
Because 1501A and 1501B are reported as integers, the only way to get that number reported to a useful precision is for Y to be very large in magnitude and X to be very small. And of course getting Y large in magnitude means losing a crapload of matches. Getting X to be very small was accomplished via the log files. The game doesn’t tell you your mythic percentile when you’re top-1500, but the logfile stores your percentage of the lowest-rated Mythic. So the lowest-rated Mythic is 100% in the logfile, but once the lowest-rated Mythic goes negative from losing a lot of matches, every normal Mythic will report a negative percentile. By conceding until the exact match where the percentile flips from -1.0 to 0, that puts the account with a rating within 1 minloss of 0. So you have a very big number divided by a very small number, and you get good precision.
Doing a similar thing controlling the #1499, #1500, and #1501 allows benchmarking all 3 accounts in terms of minloss, and then playing the 1499-1500 against each other creates a match where you know the initial rating and the final rating of each participant (as a multiple of minloss), and then, along with knowing that the win:loss ratio is 3:1, making K=4*minloss plugging into the Elo formula gives
RatingChange*minloss= 4*minloss/(1+ 10^(InitialRatingDifference*minloss/400))
and you can solve for minloss, and then for K. As long as nobody randomly makes Mythic right when you’re trying to measure, which would screw everything up and make you wait another month to try again… It also meant that I’d have multiple accounts whose rating in terms of minloss I knew exactly, and by playing them against each other and accounts nowhere close in rating (min losses and max wins), and logging exactly when each account went from positive to negative, I could make sure I had the right K-value.
That latter part didn’t work. I got a reasonable value out of the first measured match- K of about 20.25- but it was clear that subsequent matches were not behaving exactly as expected, and there was no value of K, and no combination of K and minloss, that would fix things. I couldn’t find a mistake in my match logging, (although I knew better than to completely rule it out), and the only other obvious simple source of error was the 3:1 assumption.
I’d only measured 13 wins offsetting 39 losses, which looked good, but certainly wasn’t a definitive 3.0000:1. So, of course the only way to measure this more precisely was to lose a crapload of games and see exactly how many wins it took to offset them. And that came out to a breakeven win% of 24.32%. And I did it again on a bigger samples, and came out with 24.37% and 24.40%, and in absolutely wonderful news, there was no single value that was consistent with all measurements. The breakeven win% in those samples really had slightly increased. FML.
Now that the system clearly wasn’t just Elo, and the breakeven W:L ratio was somehow at least slightly dynamic, I went in for another round of measurements in May. The first thing I noticed was that I got from my initial Mythic seed to a 0 rating MUCH faster than I had when deranking later in the month. And by later in the month, I mean anything after the first day or 2 of the season, not just actually late in the month.
When deranking my reference account (the big negative number I need for precise measurements), the measured number of minlosses was about 1.6 times as high as expected from the number of matches conceded, and I had 4 other accounts hovering around a 0 rating who benchmarked and played each other in the short window of time when I controlled the #1500 player, and all of those measurements were consistent with each other. The calculated reference ratings were different by 1 in the 6th significant digit, so I have confidence in that measurement.
I got a similar K-value as the first time, but I noticed something curious when I was setting up the accounts for measurements. Whereas before, with the breakeven win% at 24.4%, 3 losses and 1 win (against much-higher rated players, i.e. everybody but me) was a slight increase in rating. Early in May, it was a slight *decrease* in rating, so the breakeven win% against the opponents I played was slightly OVER 25%, the first time I’d seen that. And as of a few days ago, it was back to being an increase in rating. I still don’t have a clear explanation for that, although I do have an idea or two.
Once I’d done my measurements and calculations, I had a reference account with a rating equal to a known number of minlosses-at-that-time, and a few other accounts with nothing better to do than to lose games to see how or if the value of a minloss changed over a month. If I started at 0, and took X minlosses, and my reference account was at -Y minlosses, then if the value of a minloss is constant, the Mythic Percentile ratio and X/Y ratio should be the same, which is what I was currently in the process of measuring. And, obviously, measuring that precisely requires.. conceding craploads of games. What I got was consistent with no change, but not to the precision I was aiming for before this all blew up.
So this meant that the rating change from a minloss was not stable throughout the month- it was much higher at the very beginning, as seen from my reference account, but that it probably had stabilized- at least for my accounts playing each other- by the time the 1500th Mythic arrived on May 7 or 8. That’s quite strange. Combined with the prior observation where approximately the bare minimum number of games to make mythic did NOT cause an increase in the minloss value, this wasn’t a function of my games played, which were already far above the games played on that account from deranking to 0.
In Glicko, the “K-value” of a match depends on the number of games you’ve played (more=lower, but we know that’s irrelevant after this many games), the inactivity period (more=higher, but also known to be irrelevant here), and the number of games your opponent has played (more=higher, which is EXACTLY BACKWARDS here). So the only Glicko-relevant factor left is behaving strongly in the wrong direction (obviously opponents on May 1 have fewer games played, on average, than opponents on May 22).
So something else is spiking the minloss value at the beginning of the month, and I suspect it’s simply a quickly decaying function of time left/elapsed in the month. Instead of an inactivity term, I suspect WotC just runs a super-high K value/change multiplier/whatever at the start of the month that calms down pretty fast over the first week or so. I had planned to test that by speedrunning a couple of accounts to Mythic at the start of June, deranking them to 0 rating, and then having each account concede some number of games sequentially (Account A scoops a bunch of matches on 6/2, Account B scoops a bunch of matches on 6/3, etc) and then seeing what percentile they ended up at after we got 1500 mythics. Even though they would have lost the same number of matches from 0, I expected to see A with a lower percentile than B, etc, because of that decaying function. Again, something that can only be measured by conceding a bunch of matches, and something in the system completely unrelated to the Glicko they told us they were running. If you’re wondering why it’s taking months to try to figure this stuff out, well, it’s annoying when every other test reveals some new “feature” that there was no reason to suspect existed.
Problems
Rating-based pairing below Mythic is absurdly exploitable and manifestly unfair
I’m not the first person to discover it. I’ve seen a couple of random reddit posts suggesting conceding a bunch of matches at the start of the season, then coasting to Mythic. This advice is clearly correct if you just want to make Mythic. It’s not super-helpful trying to make Mythic on day 1, because there’s not that much nonsense (or really weak players) in Diamond that early, but later in the month, the Play button may as well say Click to Win if you’re decent and your rating is horrible.
When you see somebody post about their total jankfest making Mythic after going 60% in Diamond or something, it’s some amount of luck, but they probably played even worse decks, tanked their rating hard at Diamond 4, and then found something marginally playable and crushed the bottom of the barrel after switching decks. Meanwhile, halfway decent players are preferentially paired against other decent players and don’t get anywhere.
Rating-based pairing might be appropriate at the bottom level of each rank (Diamond 4, Plat 4, etc), just so people can try nonsense in ranked and not get curbstomped all the time, but after that, it should be random same-rank pairing with no regard to rating (using ratings to pair in Draft, to some extent, has valid reasons that don’t exist in Constructed, and the Play Queue is an entirely different animal altogether).
Of course, my “should” is from the perspective of wanting a fairer and unexploitable ladder climb, and WotC’s “should” is from the perspective of making it artificially difficult for more invested players to rank up by giving them tougher pairings (in the same rank), presumably causing them to spend more time and money to make progress in the game.
Bo3 K is WAY too high
Several things should jump out at you if you’re familiar with either Magic or Elo. First, given the same initial participant ratings, winning consecutive Bo1 games rewards fewer points (X + slightly fewer than X) than winning one Bo3 (~2.2X), even though going 2-0 is clearly a more convincing result. There’s no rating-accuracy justification whatsoever for Bo3 being double the K value of Bo1. 1.25x or 1.33x might be reasonable, although the right multiplier could be even lower than that. Second, while a K-value of 20.5 might be a bit on the aggressive side for Bo1 among well-established players (chess, sports), ~45 for a B03 is absolutely batshit.
Back when WotC used Elo for organized play, random events had K values of 16, PTQs used 32, and Worlds/Pro Tours used 48. All for one B03. The current implementation on Arena is using ~20.5 for Bo1 and a near-pro-tour K-value for one random Bo3 ladder match. Yeah.
The ~75%-25% cap is far too narrow
While not many people have overall 75% winrates in Mythic, it seems utterly implausible, both from personal experience and from things like the MtG Elo Project, that when strong players play weaker players, the aggregate matchup isn’t more lopsided than that. After conceding bunches of games at Plat 4 to get a low rating, my last three accounts went 51-3, 49-1, 48-2 to reach Mythic from Plat 4. When doing my massive “measure the W:L ratio” experiment last month, I was just over 87% winrate (in almost 750 matches) in Mythic when trying to win, and that’s in Bo1, mostly on my phone while multitasking, and I’m hardly the second coming of Finkel, Kai, or PVDDR (and I didn’t “cheat” and concede garbage and play good starting hands- I was either playing to win every game or to snap-concede every game). Furthermore, having almost the same ~75%-25% cap for both Bo1 and Bo3 is self-evidently nonsense when the cap is possibly in play.
The Elo formula is supposed to ensure that any two swaths of players are going to be close to equilibrium at any given time, with minimal average point flow if they keep getting paired against each other, but with WotC’s truncated implementation, when one group actually beats another more than 75% of the time, and keeps getting rewarded as though they were only supposed to win 75%, the good players farm (expected) points off the weaker players every time they’re paired up. I reached out to the makers of several trackers to try to get a large sample of the actual results when two mythic %s played each other, but the only one who responded didn’t have the data. I can certainly believe that Magic needs something that declines in a less extreme fashion than the Elo curve for large rating differences, but a 75%-25% cap is nowhere close to the correct answer.
An Overlooked Change
With the Ikoria release in April 2020, Gold was changed to be 2 pips of progress per win instead of 1, making it like Silver. This had the obvious effect of letting weak/new players make Platinum while before they got stuck in Gold. I suspected that this may have allowed a bunch more weaker players to make it to Mythic late in the month, and this looks extremely likely to be correct.
I obviously don’t have population data for each rank, but since Mythic resets to Plat, I created a toy model of 30k Plats ~N(1600,85), 90k Golds ~N(1450,85), 150k Silvers ~N(1300,85) constant talent level, started each player at rating=talent, and simulated what happened as it got back to 30k people in Mythic. In each “iteration”, people played random Bo1 K=22 matches in the same rank, and Diamonds played 4 matches, Plats 3, Golds/Silvers 2 per iteration. None of these are going to be exact obviously, but the basic conclusions below are robust over huge ranges of possibly reasonable assumptions.
As anybody should expect, the players who make Mythic later in the month are much weaker on average than the ones who make it early. In the toy model, the average Mythic talent was 1622, the first 20% to make Mythic are over 1700 talent on average (and almost nobody got stuck in Gold). The last 20% are about 1560. The cutoff for the top-10% talentwise (Rank 3000 out 30000) is about 1790. You may be able to see where this is going.
I reran the simulation using two different parameters- first, I made Gold the way it used to be- 1 pip per win and per loss. About 40% of people got stuck in Gold in this simulation, and the average Mythic player was MUCH stronger- 1695 vs 1622. There were also under 1/3 as many, 8800 vs 30,000 (running for the same number of iterations). The late-month Mythics are obviously still weaker here, but 1650 here on average instead of 1560. That’s a huge difference.
I also ran a model where Silver/Gold populations were 1/4 of their starting size (representing lots of people making Plat since it’s easy and then quitting before they play against those in the higher ranks). That’s 30k starting in Plat and 60k starting below Plat who continue to play in Plat, which seems like a quite conservative ratio to me. This came out roughly in the middle of the previous two. The average Mythic was 1660 and the late-season Mythics were around 1607 on average. It doesn’t require an overwhelming infusion into Plat to create a big effect on who makes it to Mythic late in the month.
Influx of Players and Overrated Players
The first part is obvious from the previous paragraph. A lot more people in Mythic is going to push the #1500 rating higher by variance alone, even if the newbies mostly aren’t that good.
Because WotC doesn’t use anything like a provisional rating, where a Mythic rating is based on the first X number of games at Mythic, and instead seems to give everybody fairly similar ratings throughout the month when they first make Mythic, the players who make it late in the month are MASSIVELY overrated relative to the existing population, on the order of 100+ Elo or more. Treating early-season Mythics and late-season Mythics as separate populations, when two players from the same group play each other, the group keeps the same average rating, When cross-group play happens, the early-season Mythics farm the hell out of the late-season Mythics (because they’re weaker, but rated the same) until a new equilibrium is reached. And with lots more (weaker) players making Mythic because of the change to Gold, there’s a lot of farming to be done.
This effectively makes playing late in the month positive-sum for good players because there are tons of new fish to farm showing up every day. It also indirectly punishes people who camp at the end of the month because they can’t collect the free points if they aren’t playing. This was likely always a significant cause of rank decay, but the easier path to Mythic gives a clear explanation of why rank decay is so much more severe now than it was pre-Ikoria: more players and lots more fish. The influx of weak players also means more people in the queue for good players to 75-25 farm, even after equilibration, but I expect that effect is smaller than the direct point donation.
New-player ratings are a solved problem in chess and were implemented in a proper Glicko framework in the mid-90s. WotC used the dumb implementation, “everybody starts at 1600”, for competitive paper magic back in the day, and that had the exact same problem then as their Mythic seeding procedure does now- people late to the party are weaker than average, by a lot, and while their MTG:A implementation added a fancy wrapper, it still appears to be making the same fundamental mistake that they made 25 years ago.
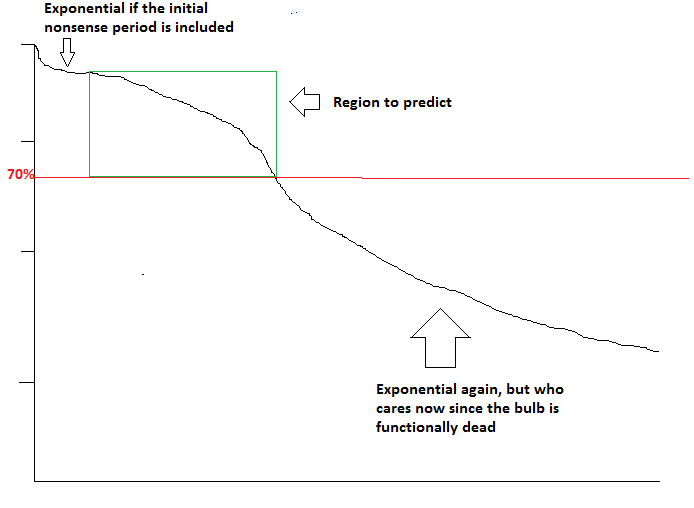
This is a graph of the #1500 rating in April as the month progressed. I got it from my reference account’s percentile changing (with a constant actual rating) as the month progressed.

The part on the left is when there are barely more than 1500 people in Mythic at all, and on the right is the late-month rating inflation. Top-1200 inflation was likely even worse (it was in January at least). The middle section of approximately a straight line is more interesting than it seems. In a normal-ish distribution, once you get out of the stupid area equivalent to the left of this graph, adding more people to the distribution increases the #1500 rating in a highly sub-linear way. To keep a line going, and to actually go above linear near the end, requires some combination of beyond-exponential growth in the Mythic population through the whole month and/or lots of fish-farming by the top end. I have no way to try to measure how much of each without bulk tracker data, but I expect both to matter. And both would be tamped down if Gold were still +1/-1.
Conclusions
Cutting way back on rating-based pairing in Constructed would create a much fairer ladder climb before Mythic and take away the easy-mode exploit. Bringing the Bo3 K way down would create a more talent-based distribution at the top of Mythic instead of a giant crapshoot. A better Mythic seeding algorithm would offset the increase in weak players making it late in the month. The ~75-25 cap.. I just don’t even. I’ll leave it to the reader’s imagination as to why their algorithm does what it does and why the details have been kept obfuscated for years now.
P.S. Apologies to anybody who was annoyed by queueing into me. I was hoping a quick free win wouldn’t be that bad. At Bo3 K-values, the rating result of any match is 95% gone inside 50 matches, so conceding to somebody early in the month is completely irrelevant to the final positioning, and due to rating-based pairing, I didn’t get matched very often against real T-1200 contenders later on. Going over 100 games without seeing a single 90% or higher was not strange.